
De site van klas6musical.nl wordt telkens korte tijd bewoond door de zesde klas, en een paar maanden na het eind van het schooljaar leeggemaakt voor de volgende klas.
Bij de eerste versie heb ik aangeboden een statische kopie te maken als aandenken. Na een paar keer mijn tanden stukgebeten te hebben op de conversie van dynamische WordPress-site naar statisch archief van HTML-pagina’s en toebehoren, is het een tijd blijven liggen. Nu is het toch bijna afgerond.
Wat moest er gebeuren:
- Homepagina downloaden
- recursief de links volgen
- Pagina’s en multimedia-inhoud downloaden
Voor het downloaden heb ik HTTrack gebruikt. Na wat testen heb ik een bruikbaar archief met deze opdrachtregel:
httraqt -q -%i -i https://www.klas6musical.nl/ -r8 -%e1 -C2 -t -%P -n -s2 -z -%s -%u -N0 -p7 -D -a -K0 -m0,0 -c8 -%k -f2 -A0 -F "Mozilla/5.0 (X11; U; Linux i686; I; rv:33.0) Gecko/20100101 Firefox/33.0" -%F "<!-- Mirrored from %s%s by HTTraQt Website Copier/1.x [Karbofos 2012-2017] %s -->" -%l ua,en -O /home/wbk/tmp/webarchives/klas6musical/ +*.png +*.gif +*.jpg +*.css +*.js -ad.doubleclick.net/*Er zit een GUI (QT, zodoende httraqt) bij waarmee je de boel kunt tunen. Ik weet de betekenis van alle switches niet meer. De eerste -r8 is het aantal recursies; het stukje ‘Mozilla…’ is hoe/als welke browser HTTrack zich voordoet. Met -O wordt de locatie opgegeven waar alles opgeslagen wordt; de +’jes geven de bestandstypen die wel gedownload moeten worden, naast HTML, de -‘etjes wat er niet gevolgd moet worden (beperkt tot een advertentienetwerk, met doubleclick werd het archief overspoeld).
Het resultaat: 8000 bestandjes, verdeeld over 5000 directories, totaal anderhalve GB aan data. Klaar!
Klaar? Nee, helaas. Elke directorie is een website waar iets van gedownload is. Vijfduizend websites dus. Van de 5000 directories zijn er maar een stuk of 20 waar we in geinteresseerd zijn. Alle (overige) advertentienetwerken, 20xInstagram, 200xFacebook, 1000x content delivery networks, 2000x Google sites, allerlei overige sites.
Na flink snoeien, is dit wat er over is:
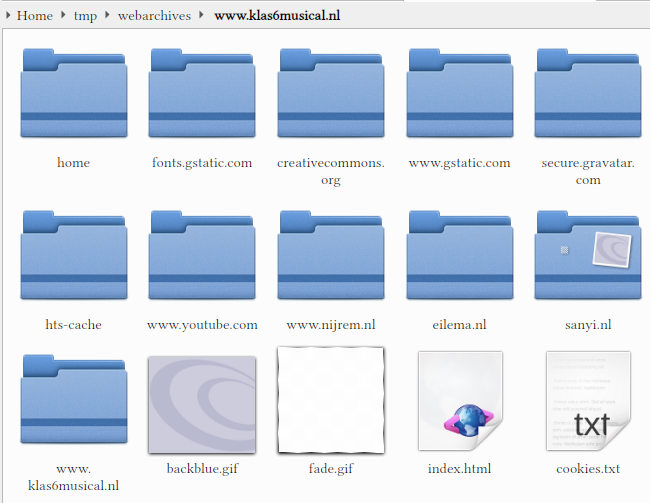
Het gaat vooral om www.klas6musical.nl, natuurlijk.
Opruimen is wel netjes natuurlijk, en scheelt later een hoop tijd (kopieren naar USB-stik kostte ~4 uur…) maar als alles al werkte zou ik daar waarschijnlijk minder aandacht aan besteed hebben. Maar alles werkte nog niet.
Dit moest gerepareerd worden :
- Plaatjes op de site waren gedownload, maar werden niet getoond
- Filmpjes werden wel getoond, maar waren niet gedownload.
De plaatjes zagen er zo uit:
(todo, copy/paste screenshot)
De oorzaak zit in de opbouw van de pagina. Er wordt voor verschillende schermformaten een mooie lijst met plaatjes gereserveerd. Na het downloaden als statische bestanden in verschillende directories zorgt dat het niet meer werkt. Misschien beveiliging van de browser, die voorkomt dat een webpagina gegevens van willekeurige directories kan lezen, of een HTML-stuurcode die niet goed werkt met locale bestanden.
Na wat uitproberen, heb ik gevonden hoe ik de gallerij-functionaliteit op genuanceerde wijze kapot kan maken door een HTML-tag te vervangen. Oorspronkelijk stond er een srcset; dat werkte niet. Comment leek me ook wel eens geen fout te kunnen geven. Dat werkte! Daarna voor alle bestanden vervangen:
grep -rl srcset .|grep html |xargs sed -i 's/srcset/comment/g'Alle plaatjes worden nu getoond. De link is echt stuk, dus inzoomen is er niet bij, maar als het nodig is kun je de foto gewoon ‘los’ openen.
Dan de filmpjes. Op het moment staan ze nog op Youtube, de meeste, maar je weet niet hoe lang het blijft staan. En ze staan niet in het archief, terwijl dat juist het idee was. Youtube-dl to the rescue.
Youtube-dl geef je een link van Youtube, en youtube-dl verzameld alle stukjes film en maakt er een complete film van. Daarvoor heb je wel alle Youtube-links van de hele site nodig.
Alle Youtube-links blijken in de www.youtube.com/embed-directorie te staan. De links naar alle filmpjes heb ik verzameld door:
# Ga naar de juiste directorie,
# cd /home/wbk/tmp/webarchives/www.klas6musical.nl/www.youtube.com/embed
# Verzamel _alle_ links:
# cat -- *html |grep 'Mirrored from ' >> links.txtHet bestandje links.txt heeft nu alle links, maar wel met wat rommel er omheen. Die rommel is elke keer hetzelfde, en is met zoeken en vervangen snel weg.
# Door de opbouw van de HTML-bestanden heb ik nu alles dubbel. Sort kan ontdubbelen:
# sort -u links.txt > links_uniek.txtHet resulterende bestandje is een lijst met kale links die er uitzien als https://youtu.be/Mmqn7xp8kIM ; die voer ik aan youtube-dl die ze download naar de ‘huidige’ directory, films:
# cd /home/wbk/tmp/webarchives/www.klas6musical.nl/www.klas6musical.nl/films
# youtube-dl -a links_uniek.txt Youtube-dl geeft standaard als naam de titel van de video + de code in de link. Die code ziet er niet mooi uit, maar die heb ik nodig om het bestand weer te kunnen koppelen in de site zelf.
Elke pagina waar een film op voorkomt, bestaat uit de pagina zelf en een ‘bakje’ (“div”) waar een Youtube-pagina uit de youtube.com/embed directory in zit. Die Youtube-pagina is tig A4’tjes aan tekst groot, en bestaat onder andere uit een videospeler en een verwijzing naar de locatie bij Google waar de film opgeslagen is.
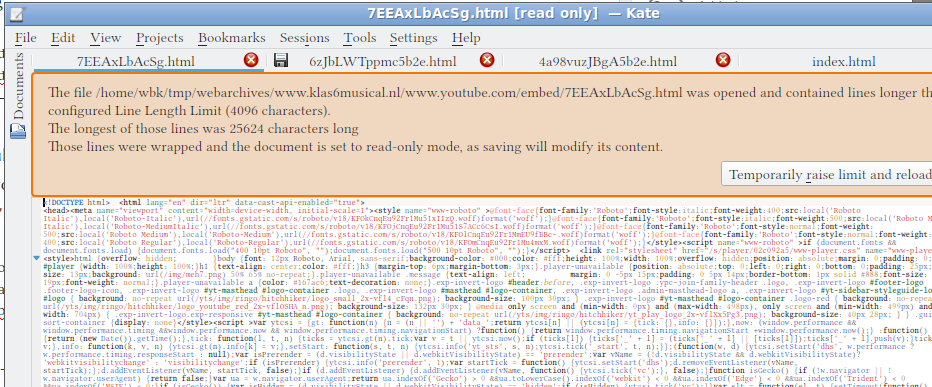
Maar die willen we dus niet gebruiken. Zelfde techniek als bij de niet getoonde plaatjes: een botte bijl en een paar keer proberen. De duizenden regels code vervang ik door vier regels tekst die proberen de video te laden vanuit het archief:

Bij het koppelen gaat het om de geselecteerde tekst, dat is de naam van het videobestand. Sommige gaan niet goed: een naam die begint met ‘#’ werkt niet, video’s van het type .mkv kan de browser vaak niet rechtstreeks tonen. Dat betekent naam veranderen (bij #) of een link in plaats van een embedded video maken (met <a href=’../../het/zelfde/pad.mkv’>mooie naam</a>).
Voor het gemakkelijk kopieren/plakken:
<div id="videoDiv">
<video id="video" src="../../www.klas6musical.nl/films/Aflevering 11 vervolg Telefoongesprek-6zJbLWTppmc.mp4" width="70%" controls>
</div>
<!--End videoDiv-->Er zijn zo’n 250 bestanden in de youtebe.com/embed-directory, maar een redelijk deel ervan blijkt nog naar advertenties de linken: weg ermee.
Samengevat:
- Site downloaden met
- httraqt -q -%i -i https://www.klas6musical.nl/ -r8 -%e1 -C2 -t -%P -n -s2 -z -%s -%u -N0 -p7 -D -a -K0 -m0,0 -c8 -%k -f2 -A0 -F “Mozilla/5.0 (X11; U; Linux i686; I; rv:33.0) Gecko/20100101 Firefox/33.0” -%F “” -%l ua,en -O /home/wbk/tmp/webarchives/klas6musical/ +.png +.gif +.jpg +.css +.js -ad.doubleclick.net/
- Gallerij ‘repareren’ door op de hoofd-directory:
- grep -rl srcset .|grep html |xargs sed -i ‘s/srcset/comment/g’
- Filmpjes downloaden met youtube-dl
- Linkjes naar de filmpjes corrigeren