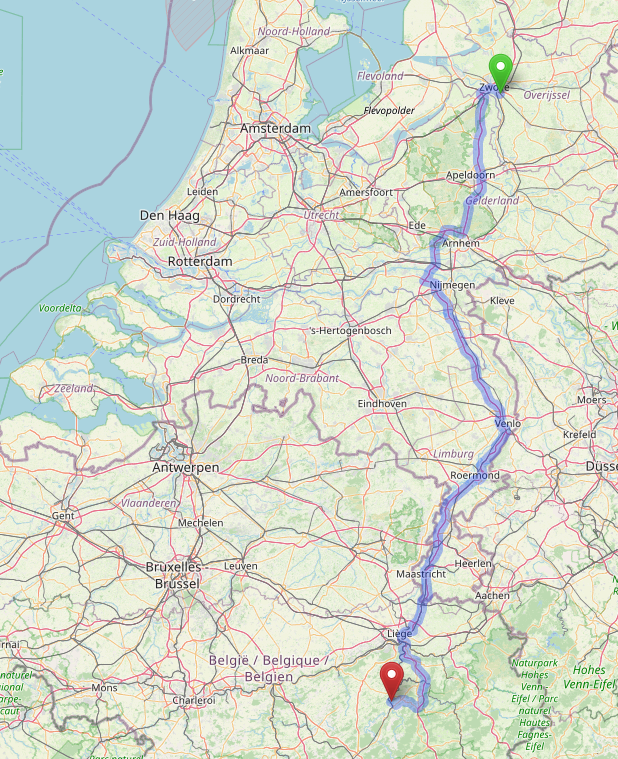
Dag 1 (24) – Naar Hamburg met stop in Bremen
Het kan zijn dat we een milieusticker moeten halen om op het raam te plakken. Een sticker kunnen we krijgen bij een Dekra-, GTÜ- of TÜV-locatie. Het lijkt er in de eerste instantie op dat voor Bremen noch Hamburg een milieuzone geldt.
- Naar Bremen:
- Iets meer dan 200 km, maar vooral over kleinere wegen lijkt het; we zijn volgens de routeplanner krap 3 uur onderweg.
- Route: vanaf Zwolle door de Hessenpoort over de N758 om Nieuwleusen heen dan N377 richting Dedemsvaart en Gramsbergen, daar de grens over richting Emlichheim en Meppen.
We zijn dan halverwege Bremen. De enige plaats van meer dan drie huizen op de route is dan nog Werlte; vanaf daar achtereenvolgens Vrees, Garrel, Beverbruch, Huntlosen, Sandhatten, Kirchhatten, Dingstede en Delmenhorst. –> dat was dus ook de voetgangersplanning. De link geeft een autoplanning.
- De batterij zal in Bremen op zo’n 25% zitten; met 50% hebben we al ruim voldoende voor Hamburg. Als we wat laden terwijl we wat eten/drinken en rondkijken in Bremen is de batterij bijna vol.
- Naar Hamburg:
Vanuit Bremen in noordoostelijke richting, het eerste plaatsje op de kaart is Lilienthal. Daarna Tarmstedt en Zeven. Hamburg zal al lang op de borden staan voor we door Buxthude rijden aan de Zuidkant van de Elbe … Ik had de routeplanner op voetganger staan. - In Oostelijke richting over de A1, vlak onder Hamburg een paar kilometer de A261 die overgaat in de A7. Over de Elbe afslag 29, Hamburg-Othmarschen, daar rechts de Behringstrasse afrijden. Na twee kilometer onder het station door, dan niet direct na de tunnel maar de volgende rechtsaf naar de Goetheallee.
- Overnachting: Meiningen Hamburg ; hostel-met-familie-kamers. Redelijk betaalbaar, goed geslapen met z’n viertjes op een kamer. Niet zo prettig: het raam konden we niet openzetten vanwege rokers buiten op de stoep voor het gebouw. Het probleem is bekend, maar er is nog geen oplossing voor. Opladen mochten we op 230V in de parkeergarage doen.
- Eten: bij Burger Heroes aan de Reeperbaan. Hamburgers zijn niet mijn ding, maar we hebben best lekker gegeten. Als toetje bubbelthee bij Vietnamees restaurant Mekong
Dag 2 (25) – naar Vikaer strand camping aan zee bij Haderslev
Het is ongeveer 200 km van Hamburg naar de camping. Haderslev ligt nog een 20 kilometer verder naar het noorden.
- Vanuit de Goetheallee eerst in omgekeerde richting onder het spoor door, na de bocht in de weg bij de eerste grote kruising rechtsaf naar het Noorden, die weg met enkele kronkelingen blijven volgen tot de A7 richting Quickborn/Kaltenkirchen.
- De A7 heeft na 70 km een afslag naar Kiel, die nemen we niet: gewoon de A7 blijven volgen.
- De grens is bij Flensburg. Nog steeds A7 blijven volgen, het wordt even later in Denemarken de E45
- Afslag 70 bij Rodekro er van af, bij de rotonde onder de snelweg door, rotonde na het viaduct de eerste niet-snelweg afslag naar het Noorden, richting Lojt Kirkeby en daarna Genner.
- Dan naar de kust, voor Sonderballe landinwaarts buigen. Aan de andere kant van de landtong is Vikaer strand camping.
We waren al op tijd op de camping, tegen het eind van de middagpauze van de receptie. In het halve uurtje tot de receptie weer openging hebben we de camping en een stuk van het strand bewandeld. Toen we het huisje eenmaal in konden, constateerden we al snel dat er in Denemarken voor geaarde stekkers een stopcontact gebruikt wordt dat niet compatibel is met de EU.
Er leek in de buurt een doe-het-zelf zaak te zitten, in Lojt Kirkeby onderweg naar Aabenraa. Aabenraa leek groot genoeg om een paar laadpalen en een eetgelegenheid en misschien ook nog iets te zien of te doen te hebben, daarmee hadden we voldoende vulling voor de rest van de dag.
De doe-het-zelf-zaak bleek een loods op een bouwterrein in een woonwijk te zijn; de eigenaren lang genoeg op vakantie om spinnenwebben achter de kleine stoffige raampjes te hebben.
Het idee was daarna om de auto aan een lader te hangen en dan ergens wat te eten. Aabenraa bleek Deens voor ‘Wijhe’. De beloftes waarin Denemarken als het vakantieland met een electrische auto bestemeld wordt ten spijt, viel het tegen met de laadpalen in Aabenraa: een verkeersbord met een grote stekker en een pijl richting een parkeerplaats leverde niets op, de laadpaal bij Lidl was defect, de laadpalen bij de ene autodealer waren vergrendeld (en bleken na een beetje prutsen met de vergrendeling onze pasjes niet te accepteren), terwijl bij een andere autodealer er een heeeleboel demo-modellen aangesloten waren in de zaak en de laders buiten niet werkten (noch met onze pas, noch met die van hen).
Bij de Lidl zat gelukkig een doe-het-zelf-zaak die wel open was. Het personeel begreep niet echt wat ik met een adapter voor een stekker met randaarde bedoelde (ik had een voorbeeld-EU-stekker meegenomen), is het toch gelukt een adapter en een losse stekker te kopen.
Toen dat probleem opgelost was, hebben we Oyishi gevonden om sushi te eten. Dat was in een keer geslaagd: we hebben lekker en redelijk betaalbaar gegeten.
Thuis bleek de electriciteit af te slaan zodra de auto begon te laden, en hebben we bij de receptie aangeklopt voor een oplossing. Die hadden ze in de vorm van een verloop-met-telwerk van een 3-polige buitenstekker naar Deens geaard, waardoor onze nieuwe verloopstekker toch nog van pas kwam.
Dag 3 (26) – strand en omgeving verkennen: Haderslev
Een dag kijken wat er in de buurt te zien en te doen is. Resultaat: Haderslev bezoeken en boodschappen doen. Haderslev is wat groter dan Aabenraa en behalve een werkende laadpaal was er is een vijver met een parkje er omheen.
Op de camping was voldoende kook-en-bakgelegenheid om eten klaar te maken.
Dag 4 (27) – Legoland, als het weer een beetje OK is
Legoland Billund ligt een kleine 100 kilometer ten Noorden van de camping, ruim een uur rijden. Het park is open van 10u tot 20u. Kaartjes kunnen we online bestellen via de Lego-site of met een paar euro korting via een Denemarken-site; voor de rest geen korting gevonden.
We zouden eventueel een 2-dagen ticket kunnen nemen, dan kun je binnen 6 dagen nog een keer naar binnen.
Het is een kaartje voor een enkele dag geworden. De zon scheen tussen de buien door, en de meeste buien hebben we gemist door een binnen-attractie te bezoeken. Het was leuk om een keer in Legoland te zijn geweest.
Voor het eten zijn we net voor het sluiten van de keuken bij Rafaels binnengerend en hebben we lekker gegeten.
Dag 5 (28) – nog in te vullen – stranddag
bijkomen en inpakken?
Wat een geluk: op onze bijkomdag scheen de zon, en was het best ondanks de wind te doen op het strand. Het water was wat fris om in te zwemmen, maar met boek/telefoon en iets te eten en te drinken zijn we de dag doorgekomen.
Voor het eten hebben we in Haderslev een tafel gereserveerd. We hadden daar de vorige keer, buiten openingstijden, een Chinees restaurant gezien met een Vietnamese naam, en dachten daar Vietnamees te eten. Toen we er aankwamen bleken er enkel Europese stijl Chinese gerechten geserveerd te worden. Na een tijdje dwalen zijn we bij iGourmet / Elisa terechtgekomen.
Dag 6 (29) – Wandeling met hunebedden
Om het natuurschoon niet ongezien aan ons voorbij te laten gaan en ook nog iets van een actieve vakantie te beleven, zijn we op zoek gegaan naar een wandelroute. Niet te ver van de camping was een route met een paar hunebedden te vinden: “Varnaes hoved og vig”.
De hunebedden vielen een beetje tegen. Een van de twee hebben we niet gezien, omdat het ergens in het natte bos zou moeten liggen. De andere was met een paadje vanaf de wandelroute te bereiken. Waar ik een bouwwerk van steen verwacht had, was het een bouwwerk van aarde, met een kring van keien er omheen. De rest van de route was afwisselend: in de drie uur die we er over deden, hebben we seizoenen (vooral herfst) en alle landschappen die Denemarken te bieden heeft voorbij zien komen. Er waren stukjes met bomen, stukjes met gras, stukjes braakliggend terrein, stukjes agrarisch landschap, stukjes langs struiken en stukjes langs de zee.
’s Avonds was het helder. We hebben een vos op de camping zien lopen en vaagjes de melkweg.
Dag 7 (30) – andere locatie – Aarhus
Nog te bedenken: eerst verder naar het Noorden, of direct richting Kopenhagen? Het is ‘verder naar het Noorden’ geworden: Aarhus.
Aarhus is ‘de tweede stad’ van Denemarken. We konden last-minute per SMS boeken bij ‘Bed and kitchen Rugbjergvej‘. Bij aankomst bleek de site niet up-to-date: de prijzen waren niet 700, maar 800 kronen per nacht. Het appartement op de verdieping onder die van de bewoners was niet het nieuwste en in de hoeken zat hier en daar een spinnenweb, maar het was schoon, ruim en comfortabel. Geen laadmogelijkheid voor de auto, maar die was er wel in Aarhus.
Op zoek naar ‘de’ laadpaal zijn we langs een Vietnamees restaurant gekomen, wat er deze keer wel echt uitzag alsof ze ook Vietnamese gerechten bereidden. Het heet Pho C&P, we hebben er erg lekker gegeten: voor herhaling vatbaar.
Dag 8 (31) – openluchtmuseum “Den gamle by”
“Den Gamle By” is een openluchtmuseum miden in Aarhus. Het is opgezet als een klein stadje. Je komt binnen in het heden, en verder naar achteren staan steeds oudere gebouwen waardoor je in de tijd terug loopt. Het is niet verschrikkelijk groot, maar in een dag hebben we niet alles (uitgebreid) kunnen bekijken.
Onder een deel van het gebied zit een ondergrondse uitbreiding, als regulier museum ingericht. Daar begin je met de eerste nederzetting in Aarhus en vanaf daar in chronologische volgorde naar het heden.
In veel van de grotere huizen/gebouwen zijn afzonderlijke exposities ingericht.
Al met al een interessante en goed gevulde dag. Na afloop hebben we bij verschillende standjes van “Aarhus street food” gegeten. De gerechten waren best betaalbaar en goed te eten. Om zonder al te veel risico van de lokale keuken te genieten, heb ik bij de tent met Deense specialiteiten iets uitgezocht. Bloemkoolstampot heb ik op een volle maag niet meer geprobeerd, maar “tarteletter” leek er nog wel in te kunnen. De tarteletter bleek een bladerdeeg bakje met kip/aspergeragout.
De auto hadden we bij de universiteit geparkeerd, redelijk in de buurt van den Gamle By, maar wel een eindje wandelen bij de haven vandaan. Parallel aan den Gamle By, tot aan de universiteit, is de botanische tuin. Het was jammer dat het al wat later was, want het was een mooie tuin om in te wandelen in plaats van enkel via de kortste route er doorheen te lopen.
Dag 9 (1) – Museum Moesgaard
Toen we zondag dingen te doen in de buurt van Aarhus zochten, kwamen we er achter dat net dat weekeind de “Moesgaard Vikingedage” geweest waren. Het was jammer dat we dat niet eerder gezien hadden en daardoor gemist hebben, maar het museum zelf was ook mooi.
Na afloop hadden we bij “Seacrets” willen eten, maar doordat er bij de betaalde parkeerplaats alleen met een Deens telefoonnummer geparkeerd kon worden, is daar niet van gekomen. We zijn voor de tweede keer bij Aarhus street food gaan eten, deze keer bij een paar andere eetgelegenheden.
Dag 10 (2) – Salling in Aarhus, naar Praesto
Woensdag was het weer een verhuisdag. We hadden naar Kopenhagen willen verkassen, maar van de paar betaalbare (en leefbare, meer dan een schuur met een kampvuur) overnachtingslocaties heeft er eentje afgezegd en de andere niet geregeerd. Een laatste hebben we zelf afgezegd toen we een huis in Praesto gevonden hadden.
Daarmee zaten we een eind bij Kopenhagen vandaan, maar niet te ver om er met een uurtje te zijn. We hadden een heel huis ter beschikking, met parkeerplaats en laadmogelijkheid aan huis, voor bijna dezelfde prijs als het huisje op de camping.
’s Ochtends zijn we nog naar Aarhus geweest. Eerst, op aanbevelen van de verhuurder, naar Salling Rooftop: een parkje van hout en staal op het dak van een warenhuis in het midden van Aarhus. Het uitzicht is beter dan vanuit het regenboogpanorama op Museum Aros, zonder dat je een kaartje nodig hebt.
Na Salling Rooftop hebben we geluncht in Pho C*P, op de terugweg naar de auto kwamen we langs een mooie spelletjes-en-LARP-winkel waar we onze ogen uitkeken en werden doorverwezen naar hun andere pand om de hoek, meer op comics gericht. Nadat we daar geslaagd waren zijn we op pad gegaan naar Praesto.
Dag 11 (3) – Praesto verkennen
Praesto is een leuk dorpje aan een baai. De zee is net een meer, zo stil staat het. Omdat het brakke water zo zoet is, staat er riet langs de kant in plaats van zoutbestendige planten, wat de indruk van een zoetwaterplas nog versterkt.
De oude dorpskern ziet er aardig uit en is overzichtelijk voor een korte wandeling. Er is een straatje met een paar winkels en er zijn twee supermarkten op loopafstand van de haven.
Die dag hebben we thuis gegeten, en plannen gemaakt voor de volgende twee dagen.
Dag 12 (4) – Kopenhagen
Met een electrische auto mag je gratis parkeren in Kopenhagen (voorzover het parkeerplaatsen betreft die door de gemeente beheerd worden). Dat was, met prijzen van rond 5 euro per uur, erg prettig.
De hoofdreden om naar Denemarken te gaan, was een winkel in Kopenhagen. Ze verkopen schoolspullen, maar verzenden niet naar Nederland. Die winkel hebben we als eerste bezocht. De rest van de dag werd zodoende mentaal verlicht door de last die van schouders gevallen was.
De rest van de dag hebben we door Kopenhagen gezworven. We hebben over de 17e-eeuwse verdedigingswallen gewandeld, we zijn in Christiania geweest (waar we bij een Tibetaans eetstalletje geluncht hebben), we zijn door Nyhavn gewandeld, hebben een barnsteen-museum(pje) bezocht, een standje gekregen van de wachten op het slotplein van de Amalienborg, om en door Kastellet gelopen onderweg naar de kleine zeemeermin. We hadden graag de botanische tuin bezocht. Daar waren we ’s ochtends al langsgekomen, maar hadden geen ingang gezien. Het bleek dat alle ingangen op een na gesloten waren wegens werkzaamheden, en die ene ingang zat natuurlijk precies aan de verkeerde kant. Toen we het park binnenkwamen, hadden we nog krap een half uur. We zijn als eerste naar het Palmhuis gelopen, maar toen we daar aankwomen werden we aangesproken door een pensionaris in een park-pak. Het was tijd om naar de uitgang te lopen, het park ging sluiten.
Onderweg naar de uitgang zijn we even op een bankje gaan zitten om de diner-opties door te nemen. Op plaatsen 1-5 stond “Sticks’n’sushi”, met een ook nog een paar locaties rond de 10e plaats. Er bleek er ook nog een niet al te ver van de botanische tuin, op weg naar de auto, te zitten.
Daar aangekomen was er nog een tweepersoonstafeltje met vier stoelen beschikbaar op het terras, met risico op rokende buren. Het meisje dat de tafel aanwees, bood aan bij de dichtstbijzijnde locatie te informeren of ze ruimte voor vier personen hadden, wat het geval was. Het bleek anderhalve kilometer de verkeerde kant op te zijn, aan de andere kant van de botanische tuin. Daarna heeft ze gebeld (met succes) of er bij de locatie in de richting van onze parkeerplaats ook ruimte was, maar het bleek dat we daarmee verder moesten lopen voor het eten en daarna nog ruim twee kilometer van de auto zaten; terug naar het eerste alternatief. Na al het geregel en een wandeling zijn we goed aangekomen en hebben we niet goedkoop, maar wel lekker gegeten.
Dag 13 (5) – Mons Klint
Praesto ligt op hetzelfde eiland als Kopenhagen, Zeeland. Ten zuiden van Zeeland ligt Mon (Meun, met een streepje door de o, net als bij Praesteu). Aan de Oostkust van Mon zijn krijtrotsen: Mons Klint.
Mons Klint is een klein uur bij Praesto vandaan, maar omdat we niet zo vroeg vertrokken waren we er pas na de middag. Dat is wel jammer: aan de oostkant heb je natuurlijk ’s ochtends zon, nu liepen we veel in de schaduw. Desondanks was het de moeite waard.
In het krijt zijn fossielen te vinden. Daar hebben we nog wel een beetje naar gezocht, maar we hadden niet veel geluk.
Mon is naar mijn idee het mooiste stukje Denemarken waar we geweest zijn, maar van de drie restaurants was er eentje gesloten, eentje was een pizzeria (natuurlijk) en de andere sushi (wat we net gehad hadden). Onderweg naar huis hebben we gezocht welke opties Praesto bood. Het best beoordeelde restaurant van de vijf had geen plaats toen we belden, bij nummer twee kostte een gerecht net zoveel als een week bij andere restaurants eten en voor de rest hadden we geen zin in pizza.
De dichtstbijzijnde plaats met meer dan een pizzeria is Naestved. Daarmee is alles gezegd: de restaurants die we belden gaven niet thuis, dus of ze waren opgedoekt of het telefoonnummer op de websites was niet (meer) goed. We zijn uiteindelijk bij “Wok og Chopsticks” terechtgekomen. Het personeel was vriendelijk zoals in de reviews, maar voor het eten zouden we niet terugkomen.
Uiteindelijk waren we bijtijds weer thuis
Dag 14 (6) – Op weg terug, Praesto – Stemmen
We hadden de avond van tevoren gedacht in een dag terug te reizen, maar het bleek dat de 600-km-route met de veerboot over ging van Lolland naar Duitsland. Dat gaf veel uitzoekwerk, daarom besloten we in twee dagen terug te reizen via dezelfde route als we gekomen waren. Overnachten zouden we in “Hotel Landgut Stemmen“.
Om te voorkomen dat de veer-route genomen werd door de navigatie, gaf ik Odense in als tussenstop; later heb ik die verwijderd om omwegen te voorkomen. Dat moment heeft de navigatie meteen aangegrepen om een route via een andere veerboot te selecteren, waar we pas achter kwamen toen voorbij Bojden de weg ophield en er een boot voor ons in het water lag. Toen zijn we alsnog met de boot gegaan en hebben we wat uitgewaaid aan dek.
Bij Fynshav kwamen we weer aan land met nog 300 km te gaan. Het werd ongeveer tijd wat te eten, en na te denken over waar we zouden avondeten: Kiel, Hamburg, Hotel?
Al rijdende kwamen we daar niet uit; met een file in het vooruitzicht zijn we bij Schuby van de snelweg gegaan om de opties door te nemen. We hadden zeker voldoende batterij om Kiel te halen (als in, om er te komen, niet als activiteit); Hamburg net niet. Na een tijdje peinzen zijn we eerst maar naar een laadpaal gereden om in ieder geval niet door de batterij beperkt te zijn. Naast de laadpaal zagen we “Kaplan Doner”, een shoarmarestaurantje (zonder eigen website), waar we naartoe liepen met het idee niet op een lege maag na te hoeven denken.
De porties bleken groot zat, en het smaakte beter dan verwacht. Toen we onze bordjes leeg hadden, konden we er zeker tot het avondeten tegenaan en was de batterij vol genoeg om niet meer te hoeven stoppen.
Zonder touristische tussenstop kwamen we bovendien voor sluitingstijd van de keuken bij het hotel aan, dus hebben we daar gegeten. Het restaurant (“Schultens“) was erg betaalbaar, maar het eten niet om over naar huis te schrijven. Gelukkig was het hotel beter dan het restaurant, en het ontbijt was goed. Ook aan de auto was gedacht: het hotel had twee vrij snelle laadpalen, waardoor we de volgende ochtend niet alleen uitgerust en met een volle maag, maar ook met een volle batterij op pad konden.
Dag 15 (7) – Stemmen – Umleitung – thuis
Van Stemmen naar Zwolle is het ongeveer 300 kilometer; goed te doen zonder opladen als je niet te snel rijdt. Het eerste stuk was echter veel snelweg, wat snel in de reikwijdte vrat. Halverwege Bremen en de grens met Nederland kwamen daarbij nog omleidingen; daardoor kwam Nordhorn op een gegeven moment in zicht. Daar hebben we eerder gegeten en opgeladen; met een blik op de batterijmeter en de klok zijn we daar gaan lunchen. Wok. Het restaurant bleek na corona overgegaan in andere handen, maar de formule was nog hetzelfde: niet heel uitgebreid, slechte koffie en sushi met iets teveel azijn, maar verder OK. Op de koffie na beter dan bij de chopsticks in Naestved, en voor minder dan de helft van het geld.
Met alle omleidingen zijn we gaan eten voor het restaurant sloot, om daarna de auto te laden. Dat bleek niet nodig, dus we zijn meteen doorgereden. Tegen het eind van de middag was de vakantie afgelopen, en na het uitpakken van de koffers leek het halverwege de avond of we niet weggeweest waren.
Epiloog
Ik keek er niet bijzonder naar uit om in Denemarken op vakantie te gaan, met wat ik wist aan “onbekend, onbemind”: ik had geen idee wat ik er, naast Legoland, te zoeken of te vinden had.
Na de vakantie heb ik die leemte in ieder geval gevuld. Ik zou als voorproefje een week in Drenthe op vakantie gaan, bij voorkeur een week waarin het geen dag droog is. Als dat bevalt, kun je overwegen naar Denemarken te gaan: “meer” (als in: “weinig”) van hetzelfde, alleen duurder. Er zijn best mooie/aardige stukjes Denemarken, maar voor mooie/aardige stukjes <vul in> hoef je niet speciaal naar Denemarken.
Wat me bijblijft van Denemarken:
- Alles is 20% duurder (of je krijgt 30% minder) dan in NL na inflatie; eten, restaurants, pretparken, overnachtingen. Prettige uitzondering: in veel musea hoeven enkel ouders te betalen; de musea die we bezocht hebben zijn mooi ingericht.
- Huizen en gebouwen zijn ingestort, staan op instorten, zijn net voldoende opgelapt om niet in te storten of zijn na instorten net voldoende opgelapt om bewoonbaar te verklaren.
- Het landschap is net Drenthe, behalve dat de glooing in het landschap het uitzicht in de weg zit. Er is vrij veel van niets, we hebben geen noemenswaardige bossen gezien (misschien zijn die allemaal gezonken als Vikingschip), er zijn geen indrukwekkende uitzichten (de heuvels zijn hoog genoeg om in de weg te staan, maar niet hoog genoeg om er overheen te kijken); er zijn geen uitgestrekte akkers of weiden, telkens enkele velden en dan wat stenen.
- Het weer doet erg zijn best om Nederlanders zich thuis te laten voelen, maar door alle zee tussen de eilanden is er teveel wind om de regen lang vast te houden. We hebben in twee weken 1 dag zonder regen gehad, en maar een paar dagen helemaal zonder zon. Het gevolg was dat je iedere dag (behalve die drie, maar dat wisten we niet van tevoren) zowel een korte broek en paraplu (bij regen zonder wind) als een lange broek en trui (bij wind zonder regen), als een korte broek en een regenjas (bij regen met wind) als een korte broek en een t-shirt (als zowel wind als regen ontbraken) nodig had
- Denemarken is toegankelijk voor toeristen (vrijwel overal is een omschrijving in het Engels beschikbaar, en als er geen Engelstalige menukaart is, dan spreekt de bediening Engels), maar het is niet ingesteld op gelegenheidstoeristen. Op korte termijn zijn er vrij weinig overnachtingsmogelijkheden beschikbaar.
- Zonder inmenging van Google of Apple en zonder Deens telefoonnummer kun je op veel plaatsen niet betalen: de digitale ekonomie leunt zwaar op 1 app die enkel via commerciele downloadwinkels beschikbaar is, en waarvoor je een Deens telefoonnummer nodig hebt.
Adressen
MEININGER Hotel Hamburg City Center
Goetheallee 11
22765 Hamburg
Vikær Strand Camping
Dundelum 29
6100 Haderslev
74 57 54 64
Print this entry