Geen idee meer bij welke upgrade het speelde (NC18 naar NC20?), maar:
An exception occurred while executing 'ALTER TABLE oc_social_3_stream ADD nid BIGINT UNSIGNED DEFAULT NULL, ADD chunk SMALLINT UNSIGNED DEFAULT 1 NOT NULL': SQLSTATE[42000]: Syntax error or access violation: 1118 Row size too large. The maximum row size for the used table type, not counting BLOBs, is 8126. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
opgelost met:
su mysql
mysql
show databases;
use nextcloud;
show columns from oc_social_3_stream;
exit ;
cd /var/www/nextcloud/
chmod +x occ
sudo -u nextcloud ./occ maintenance:repair
Met de beschrijving op https://h30434.www3.hp.com/t5/Printing-Errors-or-Lights-Stuck-Print-Jobs/Ink-system-failed-Error-Oxc18a0101-on-photosmart-D7160/m-p/27071#M231430
Fix your HP Photosmart D7360 (Reset Code/Master Reset)
1- Turn off power and unplug from power source. 2- Open right side of printer (looking at the front). 3- Disconnect,by pulling gently, both white flat ribbon cables off the main circuit board. 4- Plug in power source and turn printer on. Wait till you get a error message and push “Ok”. 5- Unplug power source. 6- Reconnect the flat ribbon cables by aligning and carefully pushing into the conectors on the main circuit board. 7- Plug in power source and turn printer on (Printer preparing occurred). 8- voila, the nasty error message 0xc18a0001 “Ink System has Failed” is now gone. http://www.fixya.com/support/t451942-help THIS WORKED!!! Don’t throw it out try this first for: Ink system failed Error:Oxc18a0101 on photosmart D7160.
Het is best lastig de zijkant te verwijderen. Er zitten een paar schroeven in, en na het verwijderen van de schroeven zitten er weerhaakjes voor eenmalig vastzetten en niet meer losmaken. Door met beleid kracht toe te passen, is de zijkant te verwijderen zonder al te veel clips af te breken.
Een andere optie vond ik op http://www.ccl-la.com/blog/index.php/hp-photosmart-ink-system-failure-2
HP PhotoSmart “Ink System Failure” #2
January 20, 2010 by CCL_TECH Filed under: Uncategorized
For HP PhotoSmart and Deskjet printers without Fax capabilities, use this guide. Are you experiencing the ink system failure on your printer? The error is caused by air getting in the ink tubes feeding the system. This is normally cause by refilled cartridges but can be caused by any cartridge that goes very low on ink and then tries to reload ink. This reset procedure does have to be performed with a full cartridge installed. The following reset procedure will correct the issue by purging the ink tubes and flushing any air trapped in them.
This sequence works if you have a C3110, C3210 or C3310 series printer. This reset procedure should also work on any printer without FAX capabilities.
Please perform the following steps in order: 1. Make sure you have new cartridges in the printer so that it can reset 2. Press down the OK and Cancel buttons down at the same time and turn the printer off. 3. Keep holding the buttons down until the printer turns off. 4. Release the buttons. 5. Now turn the printer on while pressing the OK and Cancel buttons. It should cycle a bit then turn back off. 6. Turn the unit on again. 7. After the second time off/on the printer will recalibrate the ink cartridges, this will take about 5 minutes. 8. After calibration it should be online ready to print. Print a test page to verify operation.
You should be back up and running. If this procedure does not solve the problem then remove the cover from the printer and check the small white gear on the end of the ink pump. The gear can come off after heavy use, just push it back on and then redo the reset precedure as described above.
Proxmox biedt een ‘bare metal’ installer, waarmee automatisch het hele systeem klaargezet wordt. Mijn eerste Proxmox-server heb ik op die manier geinstalleerd.
Voor de huidige server zou ZFS een goede keuze kunnen zijn, maar met slechts 4GB aan RAM is het al wat krap voor alleen Proxmox en enkele containers. ZFS staat er om bekend beter te werken als het zwemt in beschikbaar geheugen, omdat ik dat onvoldoende kan inschatten wil ik voor deze installatie geen ZFS gebruiken.
‘Geen ZFS’ betekent ‘geen kant-en-klare’ installer. Gelukkig is het niet heel veel werk om een standaard Debian-installatie uit te breiden met Proxmox. De kale Debian installatie zat rond 100MB geheugengebruik. Ik volg een stappenplan van de Proxmox-website. In grote lijnen:
Machine in elkaar zetten
Debian installeren.
Afhankelijkheden in inrichting goedzetten:
/etc/hosts aanpassen om het externe IP terug te geven
/etc/apt/sources* uitbreiden met de repositories van Proxmox
Proxmox installeren met apt install proxmox-ve postfix open-iscsi
De download is ~350MB, installatie voegt ~1800MB toe.
Klaar!
Nog te doen: rechten instellen, containers maken, systeem gebruiken
# df -hTt ext4
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/snelsys-root ext4 2.7G 13M 2.6G 1% /
/dev/mapper/snelsys-usr ext4 7.3G 1.1G 5.9G 15% /usr
/dev/sde2 ext4 163M 83M 68M 55% /boot
/dev/mapper/slowsys-var ext4 2.7G 153M 2.4G 6% /var
/dev/mapper/slowsys-varcache ext4 1.8G 77M 1.7G 5% /var/cache
/dev/mapper/slowsys-varlog ext4 1.8G 24M 1.7G 2% /var/log
root@thuis:~# apt install proxmox-ve postfix open-iscsi
0 upgraded, 494 newly installed, 1 to remove and 0 not upgraded.
Need to get 342 MB of archives.
After this operation, 1,742 MB of additional disk space will be used.
Do you want to continue? [Y/n]
Het liep fout; er was niet voldoende ruimte op /boot. Op de andere server is er 800MB in gebruik voor ’tig’ kernels, dat leek me wat overdreven. Hier zijn het er drie, daarvan kan er op zijn minst eentje per direct weg.
# dpkg -l | grep linux-image | awk '{print$2}'
linux-image-4.19.0-13-amd64
linux-image-4.19.0-6-amd64
linux-image-amd64
root@thuis:~# uname -a
Linux thuis 4.19.0-13-amd64 #1 SMP Debian 4.19.160-2 (2020-11-28) x86_64 GNU/Linux
# apt remove --purge linux-image-4.19.0-6-amd64
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages will be REMOVED:
linux-image-4.19.0-6-amd64*
0 upgraded, 0 newly installed, 1 to remove and 0 not upgraded.
1 not fully installed or removed.
After this operation, 269 MB disk space will be freed.
Do you want to continue? [Y/n]
...
update-initramfs: Deleting /boot/initrd.img-4.19.0-6-amd64
/etc/kernel/postrm.d/zz-pve-efiboot:
Re-executing '/etc/kernel/postrm.d/zz-pve-efiboot' in new private mount namespace..
No /etc/kernel/pve-efiboot-uuids found, skipping ESP sync.
/etc/kernel/postrm.d/zz-update-grub:
Generating grub configuration file ...
...
update-initramfs: Generating /boot/initrd.img-5.4.78-2-pve
Running hook script 'zz-pve-efiboot'..
Re-executing '/etc/kernel/postinst.d/zz-pve-efiboot' in new private mount namespace..
No /etc/kernel/pve-efiboot-uuids found, skipping ESP sync.
#
Op / is er nauwelijks wat geinstalleerd, het iz vooral /usr waar ~1500MB aan toegevoegd is (1200 netto verschil, na purge oude kernel).
Rechten toewijzen
De Proxmox-installer maakt geen gebruikers aan. De Debian-installer wel. Bovendien heb laat ik de Debian-installer root-login uitschakelen. Zodoende is de bestaande gebruiker geen gebruiker die toegang tot Proxmox heeft.
Om Proxmox via de web-interface te bedienen, moet de gebruiker ingericht worden:
De nieuwe rechten worden on-the-fly toegekend, maar bij het switchen tussen niveau’s op de web-interface komen maar enkele knoppen beschikbaar als je al ingelogd was voordat je aan de groep met ‘Administrator’-rol toegevoegd bent. Het was daarvoor in mijn geval niet voldoende uit- en in te loggen, of de pagina te verversen. De nieuwe eigenschappen werden pas zichtbaar na uitloggen, tab sluiten en inloggen in een nieuw tab.
Gegevensruimte / opslag
De servers heeft vier fysieke opslagmedia:
1x SSD /dev/sde, 80GB
9M BIOS boot, GPT-partitie voor GRUB
170M /boot
5.6G swap
13G LVM PV
13G VG ‘snelsys’
2.8G LV root
7.5G LV usr
56G vrije ruimte
3G ‘overprovisioning’, om de firmware ruimte te geven verwijderde bestanden op bestandssysteem-niveau, via LVM-pass-through als fysieke toewijzingen, de als leeg gemarkeerde sectoren te wissen. Als het goed is past de SSD-firmware dynamische wear-leveling toe, zodat die 3G vrije ruimte nomadisch over de flash-cellen rondwaart.
50G+ voor read/write caching, ongeveer 10G/TB aan HDD-ruimte. Niet veel, maar het scheelt. Waarschijnlijk maak ik een enkele VG uit de twee vrije HDD’s, zodat de caching ineens voor alle LV’s voorbereid is. Misschien 1G voor VG slowsys, zodat alles onder /var SSD-caching heeft.
1x HDD /dev/sda, 2TB, deels gebruikt:
28G LVM PV
28G VG ‘slowsys’
2.8G LV var
1.8G LV varcache
1.8G LV varlog
~2TB vrij, ik denk om een VG voor backups te maken
2x HDD /dev/sdb en /dev/sdc, ieder 2TB, leeg
Op beide schijven LVM PV’s van ~450TB, tot 98% van de volledige ruimte
Bij sommige LVM-bewerkingen is een paar MB aan vrije ruimte nodig, er is nu 40G per schijf beschikbaar voor noodgevallen.
Schijven inrichten
Zoals beschreven, op iedere schijf partities van 450GB met (in fdisk) type 31 (Linux LVM):
# fdisk -l /dev/sdb
Disk /dev/sdb: 1.8 TiB, 2000398934016 bytes, 3907029168 sectors
Disk model: WDC WD20EFRX-68A
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: gpt
Disk identifier: 2DF239C2-BCE1-674A-ACCA-F6D6C45B5649
Device Start End Sectors Size Type
/dev/sdb1 2048 951757283 951755236 453.9G Linux LVM
/dev/sdb2 951758848 1903514564 951755717 453.9G Linux LVM
/dev/sdb3 1903515648 2855271850 951756203 453.9G Linux LVM
/dev/sdb4 2855272448 3807029134 951756687 453.9G Linux LVM
In de eerste instantie een enkele partitie aan een VG toekennen
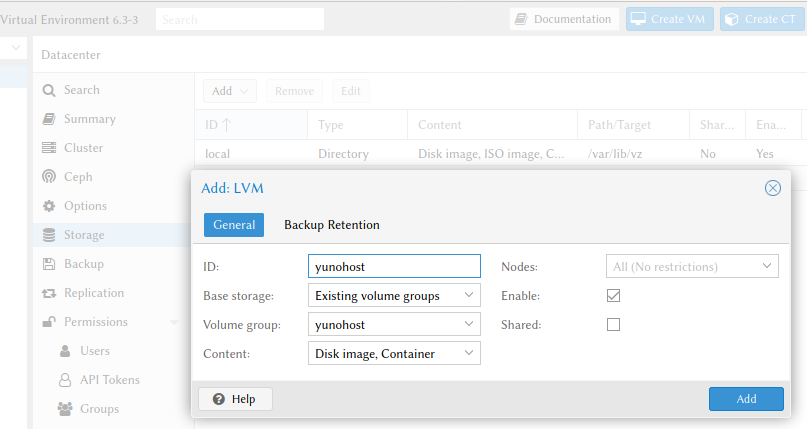
Nu in de Proxmox GUI, via Datacenter –> Storage –> Add –> LVM
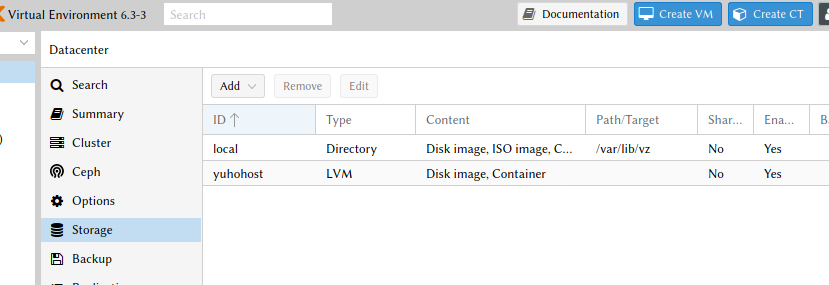
Het is verwarrend dat zowel ID als Volume group leeg en verplicht zijn. Bij ID geef je zelf een naam voor de Proxmox-storage op (yunohost, hier), bij Volume group kies je de LVM VG waar de opslagruimte in terechtkomt. Het resultaat:
ISO’s wil ik op een los volume zetten, maar Proxmox gebruikt LVM-volumes als block-storage; ISO’s moeten kunnen enkel op file-storage opgeslagen worden. Het voorbeeld voor directory-opslag laat zien dat de standaardlocatie /var/lib/vz is, daar staat nu een lijstje lege directories. Ik maak een LV met bestandssysteem, kopieer de data en koppel het op die locatie:
# ls -ls /var/lib/vz
total 20
4 drwxr-xr-x 2 root root 4096 Jan 9 19:08 dump
4 drwxr-xr-x 2 root root 4096 Dec 3 18:14 images
4 drwxr-xr-x 2 root root 4096 Jan 9 19:08 private
4 drwxr-xr-x 2 root root 4096 Jan 9 19:08 snippets
4 drwxr-xr-x 5 root root 4096 Jan 9 19:02 template
# lvcreate -n isosetc -L 4G slowsys
Logical volume "isosetc" created.
# mkfs.ext4 /dev/mapper/slowsys-isosetc
mke2fs 1.44.5 (15-Dec-2018)
Creating filesystem with 1048576 4k blocks and 262144 inodes
Filesystem UUID: 020be116-ab3f-474b-b407-a7301e59399c
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
root@thuis:~# mount /dev/mapper/slowsys-isosetc /mnt/
root@thuis:~# cp -r /var/lib/vz/* /mnt/
# echo '/dev/mapper/slowsys-isosetc /var/lib/vz ext4 defaults 0 2' >> /etc/fstab
# touch /mnt/ok
# mount /var/lib/vz
# ls /var/lib/vz
dump images lost+found ok private snippets template
#
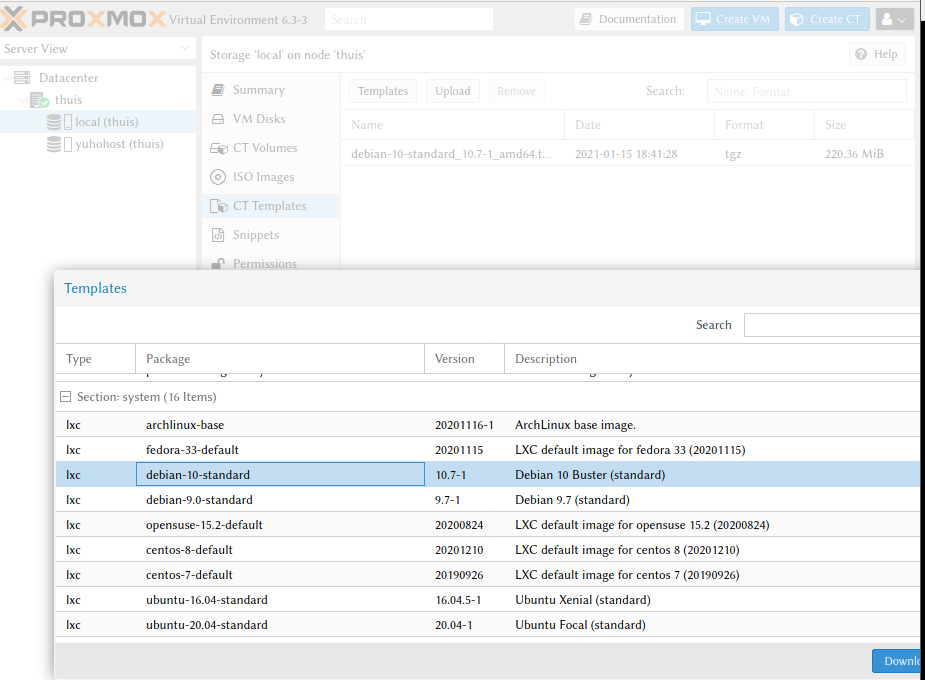
Nu kan ik met de ingebouwde template-downloader templates van Proxmox ophalen, bijvoorbeeld Debian 10 (voor het screenshot opnieuw geopend; het template is al te zien in de achtergrond)
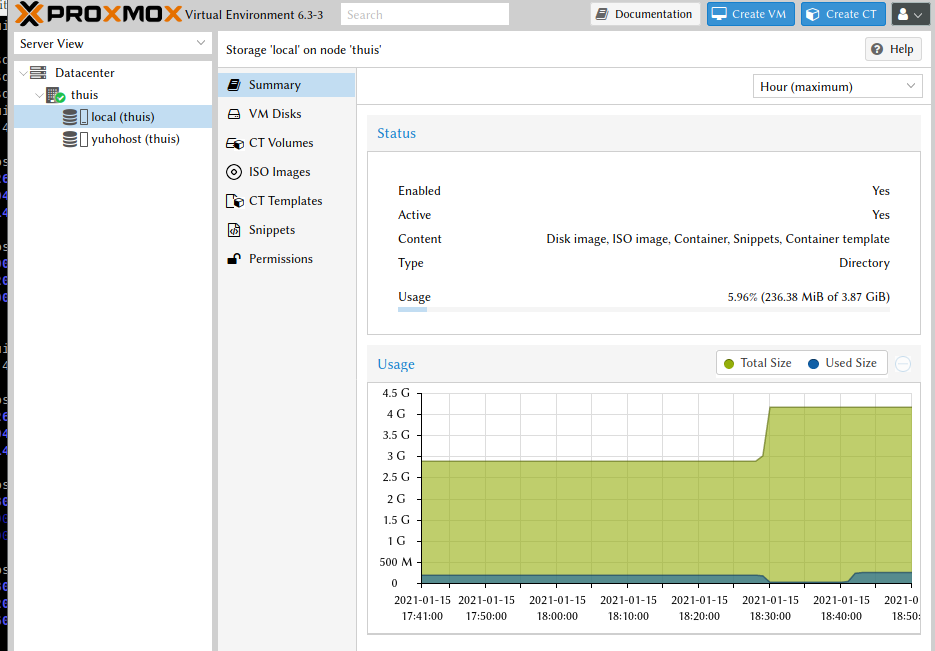
Op het samenvattingsscherm voor dit stukje opslag is te zien dat de hoeveelheid vrije ruimte en de hoeveelheid gebruikte ruimte schommelt. Tot het aankoppelen van het nieuwe volume bestonden de totale vrije ruimte en de gebruikte ruimte uit alles op LV var, aangekoppeld op /var. De vrije ruimte neemt toe van 3G (vrij op LV var) tot 4G (de vrije ruimte op LV isosetc). De gebruikte ruimte neemt af van ‘alles op /var, behalve /var/cache en /var/log’ (op hun eigen LV) naar 0, en daarna weer tot halverwege 500MB na het downloaden van het Debian-template.
Netwerk – bridge
Op de andere machine heb ik een Open vSwitch bridge gemaakt. Deze keer probeer ik het met een Linux bidge, die schijnt eenvoudiger te werken, ik gok dat dat minder resourceverbruik betekent.
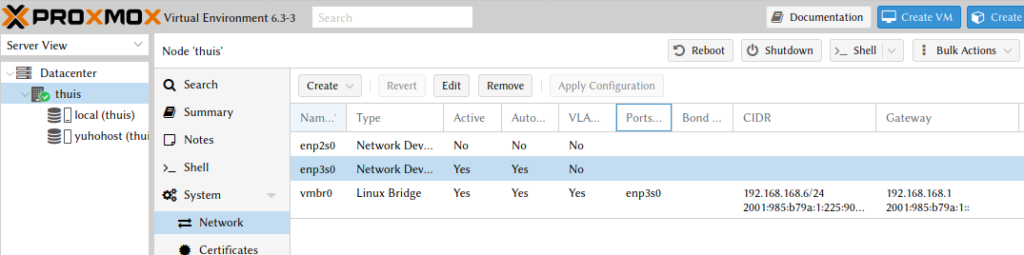
De machine heeft twee fysieke netwerkpoorten, een er van is aangesoten (enp3s0). Via ‘Create –> Linux Bridge’ heb ik de bridge toegevoegd. Zowel de netwerkkaart zelf als de bridge heb ik op autostart gezet, bij enp3s0 was dat initieel niet actief. Het resultaat in de GUI:
De configuratie kan vanuit de GUI toegepast worden als ifupdown2 beschikbaar is. Vanuit de CLI ziet het resultaat eruit als:
root@thuis:~# apt install ifupdown2
Reading package lists... Done
Building dependency tree
...
dpkg: ifupdown: dependency problems, but removing anyway as you requested:
dpkg: ifenslave: dependency problems, but removing anyway as you requested:
Saved in /etc/network/interfaces.new for hot-apply or next reboot.
root@thuis:~# cat /etc/network/interfaces
# network interface settings; autogenerated
# Please do NOT modify this file directly, unless you know what
# you're doing.
#
# If you want to manage parts of the network configuration manually,
# please utilize the 'source' or 'source-directory' directives to do
# so.
# PVE will preserve these directives, but will NOT read its network
# configuration from sourced files, so do not attempt to move any of
# the PVE managed interfaces into external files!
source /etc/network/interfaces.d/*
auto lo
iface lo inet loopback
auto enp3s0
iface enp3s0 inet manual
# This is an autoconfigured IPv6 interface
iface enp2s0 inet manual
auto vmbr0
iface vmbr0 inet static
address 192.168.168.6/24
gateway 192.168.168.1
bridge-ports enp3s0
bridge-stp off
bridge-fd 0
bridge-vlan-aware yes
bridge-vids 2-4094
#even kijken of dat zo werkt, moet later aangepast worden naar correcte IP's
iface vmbr0 inet6 static
address 2001:985:b79a:1:225:90ff:fe33:1189/128
gateway 2001:985:b79a:1::
root@thuis:~#
Container toevoegen
Met de blauwe ‘Create CT’-knop voeg je een container toe. Hierboven heb ik aan de voorwaarden om er een aan te kunnen maken voldaan:
Template – er is een template beschikbaar
Screenshots van de installatiestappen (todo…):
AKranendonk (www.kranendonk.it)
Zoek Nextcloud uit en klik erop
Bovenaan de pagina, naast ‘All files’ / ‘Alle bestanden’
Drie balletjes en twee lijntjes: delen
Login
Inloggen zou makkelijk moeten gaan: IP via DHCP,de machinenaam heb ik opgegeven, moet via lokale DNS op naam bereikbaar zijn, SSH public key heb ik meegegeven, dus login met root@fakraz zou meteen moeten werken.
Niet dus. IP opzoeken in de GUI geeft geen resultaat, er staat alleen ‘DHCP’. In de router/dhcp-server staat onder het MAC adres van de container het IP van de host. Login via console en via shell in de GUI gaat op twee manieren mis: soms is er geen login-prompt, als hij er wel is dan wordt het wachtwoord niet herkend. Blijkbaar herinner ik me niet goed wat ik ingevuld heb.
Gelukkig kan ik vanuit de host toegang krijgen tot de container, met pct:
root@thuis:~# pct enter 100
root@fakraz:~# passwd
New password:
Retype new password:
Na een reboot van de container werkt ‘opeens’ de login via public key ook, maar de login via console blijft wisselend. Het wil wel eens een paar minuten duren voordat de login-prompt op het scerm staat, maar als die er eenmaal is, lukt het wel in te loggen.
Installatie Yunohost
Het kan allemaal niet in een keer goed gaan natuurlijk. Yunohost heeft last van een DDoS-aanval, waardoor https://install.yunohost.org niet beschikbaar is. Bij het ophalen van de pagina via web.archive.org kreeg ik een certificaat-fout. Google’s cache was wel beschikbaar, maar daar krijg ik 403, geen toegang, met wget.
Tekst kopieren en in een los installatiebestandje plakken lukt wel.
Bij het uitvoeren komen er veel locale-errors voorbij:
perl: warning: Falling back to the standard locale ("C").
locale: Cannot set LC_CTYPE to default locale: No such file or directory
locale: Cannot set LC_MESSAGES to default locale: No such file or directory
locale: Cannot set LC_ALL to default locale: No such file or directory
In de container mag dpkg-reconfigure locales niet schrijven naar die locatie, gok ik, want toevoegen van de locale geeft in dpkg dezeldfe fout.
Daarom op de host de locale en_US.UTF-8 toegevoegd (naast en_IE.UTF-8); de installatie start nu en verloopt op de normale manier.
Klaar!
Daarmee draait alles:
Debian geinstalleerd
Proxmox op Debian geinstalleerd
Container met Debian op Proxmox
Yunohost op Debian in de container
Het draait, met weliswaar lage belasting op het moment, als een zonnetje. Qua hardware heeft Supermicro 2U Twin3 2015TA-HTRF 8x precies deze configuratie. Op hoofdlijnen:
De schijfruimte op de mediaserver/NAS die dienstdoet als m’n werkstation, loopt uit vrije opslagruimte.
En al een tijdje uit vrije SATA-aansluitingen. Vanwege het stroomverbruik van een PCIe-SATA-insteekkaart zit die er nog niet in, als dat al ooit komen gaat. Er ligt er een klaar, maar daar _moet_ echt een fannetje op (dus herrie), en het verbruik van ruim 20W (lokale download van huidige versie van het document) is een derde van het huidige systeem.
Kleine schijven vervangen door grotere is een andere optie. Het stroomverbruik zou, met voortgang van de techniek, voor een grotere schijf lager kunnen liggen dan met de kleinere oudere schijf. De oude schijven hebben er bijna tien jaar gebruik op zitten, vrijwel ononderbroken. Ze maken nog geen vervelende geluiden, maar preventief vervangen kan na die tijd geen kwaad.
De schijven die ik beschikbaar heb, zijn:
4TB Seagate; gevuld met incrementele back-ups via Borg-backup.
6TB Seagate; ligt al een tijdje. Het is een SMR-schijf, waarvoor ik eerst host-based SMR wilde uitzoeken. Tot zover geen succes. Blijft dus voorlopig device-based, de firmware beslist dus wat er wanneer hoe op de schijf gezet wordt, en waarzo. Of mij dat gelegen komt, heeft er niets mee te maken.
8TB Western Digital; net nieuw. De directe aanleiding om aan de slag te gaan.
480GB Crucial SSD; uit de laptop van mijn vrouw, nu die wegens plaatsgebrek vervangen is door een 960GB-exemplaar.
Zomaar een schijf erin pluggen gaat niet. In de loop van de tijd is de configuratie qua schijven gewisseld, met als kern een set van drie Western Digital 2GB schijven in RAID5 via mdadmin. Dat geeft een nuttige brutto opslagruimte van 4TB, waar LVM overheen ligt en in de eerste instantie het volledige systeem, op de groei.
Die 4TB zijn ondertussen vrijwel volledig gevuld met foto’s van de afgelopen 25 jaar. Films, video’s, muziek, boeken en ROMs staan niet meer op RAID-ondersteunde LVM. Systeemdirectories nog wel, deels op RAID1 over die drie schijven en deels in LVM op RAID5.
Er zijn zes SATA-poorten ingebouwd op het moederbord, naast de drie 2GB schijven zijn er een 3TB schijf, een kleine SSD voor caching en databases en een HDD met onbekende grootte ingebouwd.
Om een grotere schijf in te kunnen bouwen, moet er eerst eentje uit. Daarnaast wil ik de SSD vervangen door de grotere van 480GB, en de caching op LVM-niveau laten werken. Met de wirwar aan kabels is het niet heel duidelijk welke hardware op welke poort aangesloten is en zijn de schijven niet makkelijk uit de behuizing te trekken. Labels lezen op de schijven gaat dus lastig, schijven matchen met systeemeigenschappen ook.
Bij het vissen naar de huidige configuratie kwam ik wat raars tegen. Een van de 2TB WD Red-schijven deed deed zich voor als 6TB Red. Op internet wel problemen gevonden van mensen wier 6TB als 2TB gezien werd, maar niet andersom.
Ik ben een paar keer bezig geweest met Photorec, bij mogelijk gewiste SD-kaartjes en voor oude defecte schijven. Backups van MBR’s gemaakt, maar niet bewust teruggeschreven. Ik houd op die momenten in de gaten dat ik niet de verkeerde schijf aanspreek, maar je weet maar nooit.
De 6TB SMR-schijf heeft in de machine gezeten. Ik ben onlangs bezig geweest de images van de kleine schijven uit te pluizen, heb ik misschien iets overschreven? Volgens DF zitten er van WD 4 schijven in de kast: 3x Red, in RAID, en 1x de oude Green. Op onderzoek.
De bovenste schijf ligt er los in: de 2,5″ SSD van ~100GB. Zolang ik geen programma’s start waar een database achter zit, en op systeemniveau PostgresSQL en MySQL uitzet, kan ik die loskoppelen: sync disks, umount, hot-unplug power en data.
Met dat uit de weg kan ik het label van de schijf daaronder lezen: 3TB Toshiba, door het systeem herkend als een Hitachi-schijf,Hitachi Deskstar 5K3000. De schijf is van december 2012, dus vlak nadat destijds de 3,5″-productie van Hitachi via WD naar Toshiba ging.
Ik kan de schijf pas hardwarematig loskoppelen nadat de software ontkoppeld is. Onder welke koppelpunten is de data op deze schijf beschikbaar?
Spoorzoeken met mount, df, pvs, vgs, lvs en /etc/fstab. De 3TB schijf is te vinden als /dev/sdf:
root@fractal:~# fdisk -l /dev/sdf
Disk /dev/sdf: 2.7 TiB, 3000592982016 bytes, 5860533168 sectors
Disk model: Hitachi HDS5C303
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: gpt
Disk identifier: D03ED4D8-E7F1-4550-8CEE-762B1263FEBC
Device Start End Sectors Size Type
/dev/sdf1 3563204608 5860532223 2297327616 1.1T Microsoft basic data
/dev/sdf2 2237691904 3563204607 1325512704 632.1G Microsoft basic data
/dev/sdf3 2048 209717247 209715200 100G Linux LVM
Partition table entries are not in disk order.
Vanuit de fysieke partities zijn de physical volumes in LVM te vinden:
Drie PV’s in totaal, en 5 LV’s. Dat is wat ik hierboven ook vond. Om het systeem zonder problemen te kunnen starten moeten de partities niet automatisch gekoppeld worden bij het starten van het systeem. Partities die niet automatisch gekoppeld worden, maar nu wel gekoppeld zijn, zijn terug te vinden met mount of df.
Reservekopie van /etc/fstab en de mounts van de partities in commentaar zetten.
Het zou voldoende zijn de aangekoppelde bestandssystemen te syncen en los te koppelen voor ik de schijf fysiek loskoppel, maar met draaiende schijven zit me dat minder lekker dan met SSD’s. Dus: machine afsluiten, schijf loskoppelen, reboot, resultaat bekijken.
Op vrijwel alle systemen gebruik ik LVM (LVM2 tegenwoordig) voor het indelen van opslagruimte. Er zijn tegenwoordig allerlei mogelijkheden om flexibel met opslagruimte om te gaan, maar de eenvoudige systemen die ik 1-2-3 kan opnoemen (ZFS, BTRFS), zijn nog niet zo lang beschikbaar voor Linux en heb ik nog maar beperkt gebruikt.
LVM zal op bepaalde punten achterlopen, maar voldoet voor mij prima. In dit geval om een krappe home-directory wat ruimte te geven met lvextend.
Voer de opdracht eerst in testmodus (-t) uit:
root@linhovo:~# lvextend /dev/mapper/data-linh /dev/sda3 -tvrL +30G
TEST MODE: Metadata will NOT be updated and volumes will not be (de)activated.
Executing: /sbin/fsadm --dry-run --verbose check /dev/data/linh
fsadm: "ext4" filesystem found on "/dev/mapper/data-linh".
fsadm: Skipping filesystem check for device "/dev/mapper/data-linh" as the filesystem is mounted on /home/linh
/sbin/fsadm failed: 3
Test mode: Skipping archiving of volume group.
Extending logical volume data/linh to <285.58 GiB Size of logical volume data/linh changed from <255.58 GiB (65428 extents) to <285.58 GiB (73108 extents). Test mode: Skipping backup of volume group. Logical volume data/linh successfully resized. Executing: /sbin/fsadm --dry-run --verbose resize /dev/data/linh 299450368K fsadm: "ext4" filesystem found on "/dev/mapper/data-linh". fsadm: Device "/dev/mapper/data-linh" size is 274424922112 bytes fsadm: Parsing tune2fs -l "/dev/mapper/data-linh" fsadm: Resizing filesystem on device "/dev/mapper/data-linh" to 306637176832 bytes (66998272 -> 74862592 blocks of 4096 bytes)
fsadm: Dry execution resize2fs /dev/mapper/data-linh 74862592
Let op ‘/sbin/fsadm failed: 3’, omdat het bestandssysteem aangekoppeld is:
root@linhovo:~# umount /home/linh
Voer de opdracht nu uit zonder -t, om de wijziging aan de logische partitie feitelijk door te voeren en het bestandssysteem te vergroten:
root@linhovo:~# lvextend /dev/mapper/data-linh /dev/sda3 -tvrL +30G
TEST MODE: Metadata will NOT be updated and volumes will not be (de)activated.
Executing: /sbin/fsadm --dry-run --verbose check /dev/data/linh
fsadm: "ext4" filesystem found on "/dev/mapper/data-linh".
fsadm: Filesystem has not been checked after the last mount, using fsck -f
fsadm: Dry execution fsck -f -p /dev/mapper/data-linh
Test mode: Skipping archiving of volume group.
Extending logical volume data/linh to <285.58 GiB Size of logical volume data/linh changed from <255.58 GiB (65428 extents) to <285.58 GiB (73108 extents). Test mode: Skipping backup of volume group. Logical volume data/linh successfully resized. Executing: /sbin/fsadm --dry-run --verbose resize /dev/data/linh 299450368K fsadm: "ext4" filesystem found on "/dev/mapper/data-linh". fsadm: Device "/dev/mapper/data-linh" size is 274424922112 bytes fsadm: Parsing tune2fs -l "/dev/mapper/data-linh" fsadm: Resizing filesystem on device "/dev/mapper/data-linh" to 306637176832 bytes (66998272 -> 74862592 blocks of 4096 bytes)
fsadm: Dry execution resize2fs /dev/mapper/data-linh 74862592
root@linhovo:~# lvextend /dev/mapper/data-linh /dev/sda3 -vrL +30G
Executing: /sbin/fsadm --verbose check /dev/data/linh
fsadm: "ext4" filesystem found on "/dev/mapper/data-linh".
fsadm: Filesystem has not been checked after the last mount, using fsck -f
fsadm: Executing fsck -f -p /dev/mapper/data-linh
fsck from util-linux 2.33.1
linh: 74099/16752640 files (5.8% non-contiguous), 63802054/66998272 blocks
Archiving volume group "data" metadata (seqno 4).
Extending logical volume data/linh to <285.58 GiB Size of logical volume data/linh changed from <255.58 GiB (65428 extents) to <285.58 GiB (73108 extents). Loading table for data-linh (254:3). Suspending data-linh (254:3) with device flush Resuming data-linh (254:3). Creating volume group backup "/etc/lvm/backup/data" (seqno 5). Logical volume data/linh successfully resized. Executing: /sbin/fsadm --verbose resize /dev/data/linh 299450368K fsadm: "ext4" filesystem found on "/dev/mapper/data-linh". fsadm: Device "/dev/mapper/data-linh" size is 306637176832 bytes fsadm: Parsing tune2fs -l "/dev/mapper/data-linh" fsadm: Resizing filesystem on device "/dev/mapper/data-linh" to 306637176832 bytes (66998272 -> 74862592 blocks of 4096 bytes)
fsadm: Executing resize2fs /dev/mapper/data-linh 74862592
resize2fs 1.44.5 (15-Dec-2018)
Resizing the filesystem on /dev/mapper/data-linh to 74862592 (4k) blocks.
The filesystem on /dev/mapper/data-linh is now 74862592 (4k) blocks long.
root@linhovo:~# df -h /home/linh
UPDATE: ik was blij verrast dat df de ruimte wist te vinden voor de niet-aangekoppelde partitie. Omdat de beschikbare ruimte overeenkwam met wat ik verwachte, heb ik geen acht geslagen op de details.
Nu ik die bekijk, zie ik dat df wel antwoord op mijn vraag gaf, maar als resultaat de partitie toonde waarin het koppelpunt voor /home/linh zich bevind. De partitie is ondertussen verder gevuld en uitgebreid, het verduidelijkt het verhaal niet meer om de juiste output te tonen.
Les voor de volgende keer: vraag niet de vrije ruimte van het mount point op, maar de vrije ruimte van de partitie:
root@linhovo:~# df -h /dev/mapper/data-linh
"partition not mounted" (or something of that order)
Wat doet het nog? Een webserver bestaat uit een toren van losse systemen. Als een van de systemen het niet doet, stort de rest van de toren in. Vanaf de fundamenten naar boven zijn de bouwstenen die je het makkelijkste kunt controleren:
Staat ‘ie aan?
Kun je zelf alleen controleren als hij bij je thuis staat
Geeft het appparaat levenstekenen?
Kun je zelf alleen controleren als hij thuis staat
Hangt er ook vanaf wat voor appaatje je hebt
Orange Pi Zero: met seriele poort, verhaal voor een andere keer
Oude laptop: iets typen of muis bewegen
Reageert de server op pings? In het geval van osba.nl:
ping 80.127.182.180
ping 2001:985:b79a:1:6d21:81ff:a52e:6f3
ping -4 osba.nl
ping -6 osba.nl
Kun je met SSH in de server komen?
ssh admin@domeinnaam.nl
Werkt de admin-pagina nog?
ga naar het IP van je server; je kunt het vinden via ping. Bijvoorbeeld:
https://[2001:985:b79a:1:6d21:81ff:a52e:6f3]
https://80.127.182.180
https://osba.nl/yunohost/admin
Als het werkt via het IP-adres, krijg je een beveiligingswaarschuwing vanwege het certificaat (SSL of TSL). Als je browser het toestaat, kun je verder gaan met de onveilige instelling. Als je het certificaat bekijkt en je weet dat het bij je server hoort kun je ook inloggen.
Kun je inloggen op de gebruikerspagina?
Ga naar het reguliere login-adres voor Yunohost,
https://osba.nl/yunohost/sso/
Wat nu?
Het hangt er vanaf hoe ver je gekomen bent. Per nummertje:
Het makkelijkste is natuurlijk als de server gewoon thuis staat en je de stroom kunt controleren. Als het apparaatje aan een batterij hangt, kan het maar zo zijn dat er een paar dagen eerder een stekker uitgetrokken is, en dat je het nu pas merkt.
Kijken of er iets gebeurt gaat eigenlijk hetzelfde als met een laptop, mobiele telefoon of een computer. Vastlopen kan gebeuren als de voeding van de Orange Pi net niet sterk genoeg is. Hij gaat dan wel aan, maar eigenlijk doet ‘ie het voor de helft niet.
Ping kun je voor het hele internet (en alle apparaten thuis) gebruiken om te kijken of ze bereikbaar zijn op het netwerk. Het commando stuurt een berichtje voor het apparaat dat je noemt, en als dat apparaat het ontvangt, stuurt het een antwoord terug. Zo ziet het er bijvoorbeeld uit:
ping -4 osba.nl PING osba.nl (80.127.182.180) 56(84) bytes of data. 64 bytes from online.osba.nl (80.127.182.180): icmp_seq=1 ttl=64 time=0.457 ms 64 bytes from online.osba.nl (80.127.182.180): icmp_seq=2 ttl=64 time=0.092 ms
Je kan een ping sturen naar een IP-adres of naar een domeinnaam. In het geval van IP-adres, kan het een van versie 4 (vier blokjes cijfers met een punt ertussen) of van versie 6 (heel veel cijfers en letters met dubbele punten ertussen) zijn. Daarom de verschillende voorbeelden. Voor computers zijn de IP-adressen het makkelijkste. Voor domeinnamen is een extra stap via DNS nodig. Elke extra stap is een stap die kan mislukken. Als je server reageert op ‘ping domeinnaam’, dan werkt het ook met minstens een van de twee IP-versies. Andersom hoeft niet. Als het wel werkt met het IP-adres, maar niet met de domeinnaam, dan is er een probleem met DNS. Voor alle Yunohosts die ik zelf ingericht heb, gaat DNS via your-webhost.nl (met een gebruikersnaam met qb….) of via dns.he.net (met de gebruikersnaam die daar bij hoort)
Als er een reactie op de ping terugkomt, kun je proberen om met SSH in te loggen. Dat gaat met: ssh admin@domeinnaam Je logt in met het wachtwoord dat je ook voor de admin-pagina van Yunohost gebruikt (de witte pagina, met de instellingen).
Misschien is het voldoende om het systeem opnieuw op te starten. Gebruiker ‘admin’ mag dat niet, maar gebruiker ‘root’ mag dat wel. Type: sudo reboot en dan enter. De verbinding wordt verbroken. Als dat genoeg was, dan is even later je website weer terug.
Als dat niet genoeg was, dan wordt het wat lastiger. Misschien staat er iets in het logboek waarmee je op internet een oorzaak kunt vinden. Type: sudo tail -f /var/log/messages … en dan enter. De laatste regels van het logboek komen nu tevoorschijn. Als de server nog ergens mee bezig is, dan komt er een regeltje bij. Je kan stoppen met kijken door ctrl-c in te drukken. Verhaal voor een andere keer.
Soms doet de normale loginpagina het niet, maar de adminpagina het nog wel. Je kan vanuit de adminpagina naar de diagnosepagina gaan. Dat is ook nog wel een beetje lastig, maar makkelijker te lezen dan de berichten rechtstreeks in het logboek. Ik ga er nu niet verder op in.
Als we zover gekomen zijn zonder problemen, dan zou eigenlijk de website gewoon moeten werken. Probeer in te loggen op de zwarte pagina met de gekleurde blokjes. Als je standaaard naar een blog of andere pagina gaat, dan moet je achter het adres ‘/yunohost’ typen, bijvoorbeeld https://osba.nl/yunohost Je kan dan de verschillende apps proberen, om te zien of ze het allemaal niet doen, of dat er bijvoorbeeld een probleem is met alleen WordPress of alleen met Nextcloud.
Dat was een lang verhaal. Vaak als er een niet te groot probleem is, kun je met deze stappen de oorzaak vinden en verhelpen.
Software bijhouden
Als alles het doet dan is dat fijn. Maar het is wel belangrijk om bij te blijven met beveiligingsupdates. Sommige beveiligingsupdates worden door Yunohost zelf gedaan. Om volledig bij te werken, en ook nieuwe functionaliteit beschikbaar te maken, kun je het systeem bijwerken via de admin-pagina of via SSH.
update via admin-pagina
Een van de menupunten op de admin-pagina is systeem-update. Als je die aanklikt, wordt infomatie over alle updates opgehaald en weergegeven.
Daarna kun je kiezen of je het systeem wil bijwerken of de apps. In het laatste geval kun je ze ook een-voor-een bijwerken. Soms is dat nodig omdat de bovenste een probleem heeft bij de update, en de rest niet in een rijtje afgewerkt wordt. Soms wil je juist weer snel alleen het onderste programma bijwerken.
Bovenin de pagina wordt weergegeven bij welke stap van de upgrade Yunohost is: downloaden van de nieuwe versie, backup maken, installeren, etc. Daar wordt ook een berichtje gegeven als de upgrade klaar is, of als er juist iets fout gaat.
Update via SSH
Inloggen met SSH kan met een SSH-programma op je computer of op je telefoon, of via “Terminalscherm in je browser / shell in a box”. Je logt in met admin en het wachtwoord van admin (er komen bij het wachtwoord geen sterretjes of balletjes in beeld, dus gewoon typen en enter drukken).
Daarna kun je met drie commando’s het systeem bijwerken, telkens met enter achteraan de regel:
Laatst werkte Nextcloud niet meer na een upgrade. Bij het openen van Nextcloud werd een melding over onderhoudsmodus / maintenance mode getoond.
Het bleek dat Nextcloud na de update een nieuwe versie van een programmeertaal nodig had (PHP 7.3 ipv PHP 7.0). De upgrade dat wel de nieuwe versie van PHP geinstalleerd, maar gebruikte standaard nog versie 7.0. Daardoor lukte het me niet om de onderhoudsmodus te deactiveren:
gaf een foutmelding. Ik heb PHP handmatig laten wijzen naar versie 7.3 met sudo update-alternatives –set php /usr/bin/php7.3 , maar achteraf gezien had ik misschien moeten proberen de aanroep van PHP aan te passen ( dus sudo -u nextcloud /usr/bin/php7.3 /var/www/nextcloud/occ maintenance:mode –off ), dat merk ik vast later weer. Nextcloud doet het in ieder geval weer, en de rest van het systeem ook.
We hebben infrarood-vloerverwarming geïnstalleerd. De verwarming is, bij gebrek aan themostaat, nog niet aangesloten. Vanaf het begin was mijn idee om een Arduino of vergelijkbaar te gebruiken om zelf een thermostaat te bouwen. Het was niet alleen goedkoper en flexibeler, maar ook een uitstekende reden om met Arduino aan de slag te gaan.
De onderdelen zijn ondertussen aangekomen:
ESP32, het brein van elke thermostaat
Relais, voor het daadwerkelijke aan/uitschakelen van de verwarmingsfilm
10k NTC’s liggen al onder de vloer, samen met de film zelf
De afzonderlijke functies die ik nodig heb/wil integreren zijn makkelijk online te vinden, en het samenvoegen ervan ging aanvankelijk best vlot. Het resultaat was bijna wat ik nodig had, enkel de sensor voor omgevingstemperatuur en het instellen van een variabele doeltemperatuur ontbraken. En alles werkte in de verkeerde volgorde. Welke functies allemaal, en wat ging er mis in de eerste iteratie?
Temperatuur meten
Thermostaat instellen
Aan de ene kant de omgevingstemperatuur: de gewenste temperatuur in de kamer
Aan de andere kant de vloertemperatuur: de vloer mag niet warmer dan 29 graden Celsius worden
Relays aan- of uitschakelen afhankelijk van de gemeten temperatuur en de instelling van de thermostaat
Toegankelijk via WiFi op het interne domotica-netwerk
Zoals gezegd, van iedere afzonderlijke functie zijn er voorbeelden voor Arduino en, in mindere mate, voor ESP32 te vinden. Ik had uiteindelijk een programma dat:
Verbinding zoekt via WiFi
Een web-interface toont om het relais aan of uit te schakelen
De temperatuur meet als je een button op de webinterface indrukt
Het relais schakelt gebaseerd op de gemeten temperatuur
De thermostaad deed dus niets met het relais totdat je er zelf wat mee deed. Niet zo nuttig. Het moet juist andersom werken:
Bekijk de huidige staat van het relais
Staat ‘ie uit? Dan de omgevingstemperatuur vergelijken met de ingestelde thermostaatwaarde
Staat ‘ie aan? Dan de vloertemperatuur vergelijken met de ingestelde maximumwaarde
Afhankelijk van de uitkomst hierboven, het relais schakelen of in de huidige staat laten
Verbind gedurende een minuut met WiFi
Toon in die tijd de web-interface
Geef de mogelijkheid de thermostaat in te stellen
Begin van boven af aan
De volgende stap is om een domoticaserver een interface voor de thermostaat te laten serveren, en dat de ESP32 de domoticaserver zo nu en dan vraagt wat de gewenste temperatuur is. Op die manier toont de ESP32 niet zo lang een web-interface via WiFi, met zodoende minder energieverbruik en hogere veiligheidsgraad. Maar dat komt later
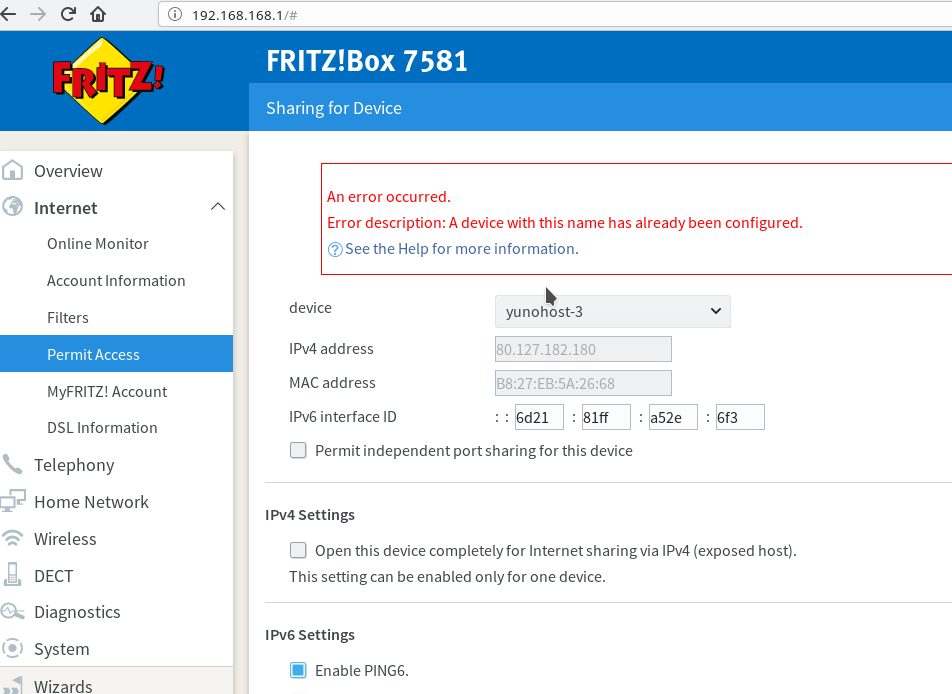
De Engelstalige versie heeft het hele verhaal, hier mijn stappen om te voorkomen dat de Fritzbox een duplicaat apparaat krijgt. Zo’n duplicaat apparaat (dezelfde hostname met twee MAC-adressen) zorgt voor een heel irritante foutmelding bij het aanmaken van een nieuwe portforwarding of het aanpassen van een bestaande:
Een publiek IPv4 toewijzen
Voor Yunohosts met Armbian op OPi Zero’s volg ik bij benadering het volgende stappenplan:
Gewoon aansluiten en een adres per DHCP laten toewijzen
Blijf van de hostname af in de Fritzbox
Configureer het systeem via SSH op het locale IP
Zorg dat zowel een verbinding via ethernet als via seriele kabel beschikbaar is
Gebruik nmtui om het publieke IP in te richten
Activeer de nieuwe inrichting nog niet
Maak de ethernetkabel los
Gebruik de seriele verbinding om het apparaatje af te sluiten
Wacht totdat de Fritzbox het apparaatje van actieve naar inactieve aansluitingen verplaatst heeft in de thuisnetwerk-instellingen
Verwijder het apparaat uit de lijst met apparaten
Dat kan enkel wanneer de FB denkt dat het apparaat inactief is
Het heeft enkel effect wanneer de naam van het apparaat niet veranderd is vanaf de eerste keer dat de FB het apparaat gesignaleerd heeft
Soms helpt het de FB eens te rebooten, maar niet altijd, en het maakt het proces ook niet altijd sneller
Zodra je ‘m verwijderd hebt, sluit de ethernetkabel weer aan
Zet het apparaatje weer aan . network manager gebruikt de nieuwe configuratie om de netwerkaansluiting in te richten
Soms zie je het apparaat niet direct staan, omdat het met een naam gebaseerd op het IP-adres in de lijst gezet wordt
Pas de (onhandige) naam niet aan
Nu is het apparaat te bereiken op het publieke IP. Het inrichten van port forwardings mag geen problemen opleveren.
Het resultaat van deel I was dat ik gebruikers op dezelfde server kon vinden: iedereen die een account op online.osba.nl heeft. Leuk, maar dat was niet wat ik voor ogen had. De afgelopen weken heb ik zo nu en dan een blik op het probleem geworpen, in de hoop dat me een makkelijke oplossing onder ogen zou komen. Helaas.
Vanavond heb ik er meer tijd dan ik had gehoopt besteed, maar ik heb wel een deel van de (weg naar de) oplossing gevonden. De test op webginger.net geeft nu een nuttig resultaat terug:
Request log
18:20:13 Looking up WebFinger data for acct:wbk@online.osba.nl
18:20:13 GET https://online.osba.nl/.well-known/webfinger?resource=acct%3Awbk%40online.osba.nl
JSON Resource Descriptor (JRD)
{
"subject": "acct:wbk@online.osba.nl",
"links": [
{
"rel": "self",
"type": "application/activity+json",
"href": "http://online.osba.nl/nextcloud/nextcloud/index.php/apps/social/@wbk"
},
{
"rel": "http://ostatus.org/schema/1.0/subscribe"
}
]
}
Dat was telkens 404, niets gevonden.
Meer details zijn (in het Engels) te vinden Yunohost forum, maar het belangrijkste deel is de benodigde configuratie en waar je het moet laten. Het configuratiebestand waar het om gaat is de nginx-configuratie op
/etc/nginx/conf.d/online.osba.nl.conf
Er zijn twee servers gedefinieerd, de onversleutelde op poort 80 en de versleutelde verbinding op poort 443. De eerste had na het installeren via Yunohost / Nextcloud alle redirects cadeau gekregen, die op poort 443 niets. Ik vond het opvallend, maar bij gebrek aan kennis van nginx deed het ook geen alarmbellen rinkelen. Het blijkt dat de verwijzingen op beid e servers gedefinieerd moeten staan, anders werkt het niet via TLS. Bovendien moet het een combinatie van doorverwijzing en herschrijven van de URL zijn:
location = /.well-known/webfinger {
rewrite ^ https://online.osba.nl/nextcloud/public.php?service=webfinger&$1 last; # $1 will use the first parameter (?resource=…)
}
Stop het stukje tussen de ‘include …’ en ‘log ..’ regels.
Ookal werkt de test op webfinger.net nu, het lukt nog niet om op de ene Nextcloud een gebruiker op een andere Nextcloud-server te vinden.
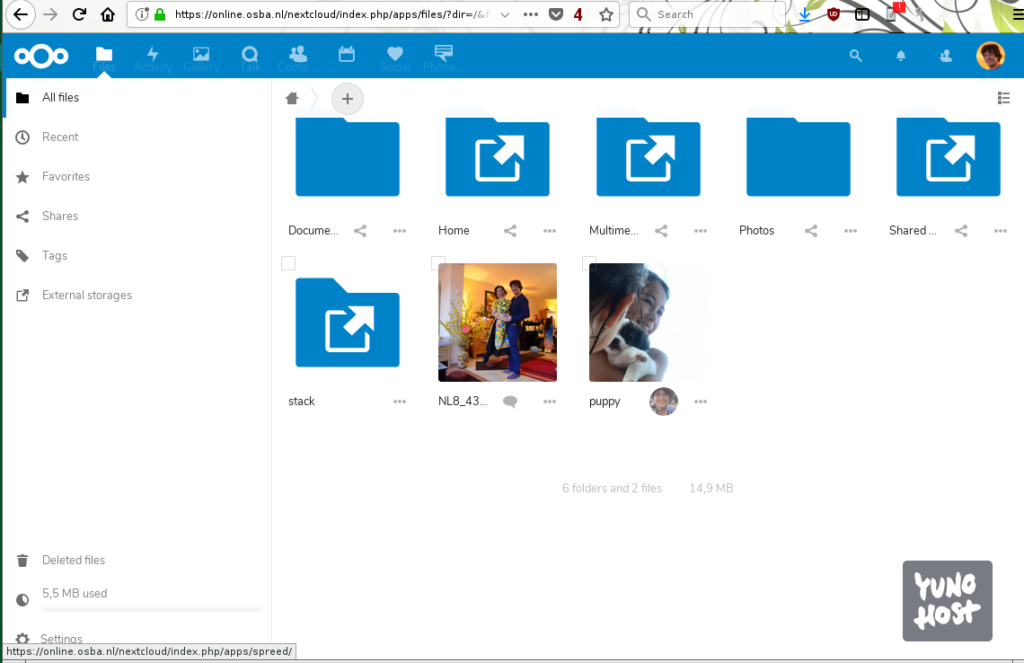
Nextcloud is een systeem om allerlei dingen die op je computer of op je telefoon staan te bewaren of te delen. Bijvoorbeeld foto’s, muziek, plaatjes, savegames of backups.
Zoek Nextcloud uit en klik erop
Je kunt gewoon inloggen op je Nextcloud door op het vierkantje de drukken en te bladeren in de bestanden die al naar Nextcloud gestuurd zijn, of je kan op je computer/telefoon instellen dat nieuwe foto’s automatisch geupload worden: backup (kopie voor de zekerheid) en synchronisatie (zodat de foto van je telefoon automatisch op je computer komt te staan).
Foto upload
Het hoofdscherm van Nextcloud ziet er ongeveer zo uit:
Nextcloud startscherm
Het ziet er een beetje uit als de lijst met bestanden op je computer, maar dan op je webserver. Als je voor het eerst kijkt, zie je dat er tijdens de installatie van het systeem al wat voorbeeldbestanden neergezet zijn. Die kun je gerust weggooien.
Een nieuwe foto kun je met het plusje naast het huisje toevoegen. Als je het plusje aanwijst, komt er een menu’tje tevoorschijn waar je kun kiezen een nieuw bestand te uploaden (‘Upload file’/’Bestand uploaden’):
Bovenaan de pagina, naast ‘All files’ / ‘Alle bestanden’
De foto is na een paar ogenblikken (afhankelijk van hoe groot de foto is en hoe snel de verbinding) te zien in de lijst met bestanden.
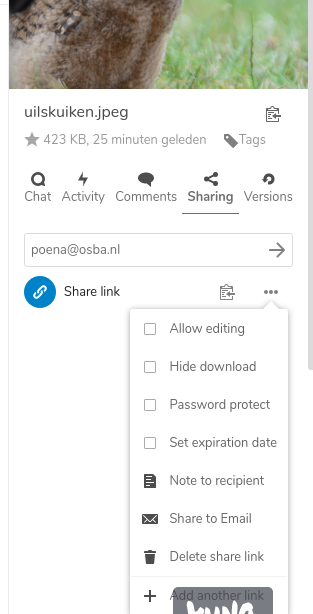
Foto delen
Drie balletjes en twee lijntjes: delen
poena@osba.nl als emailadres, of klik ‘Share link’
Onder elke foto (en elk ander bestand) staat een ikoontje, drie balletjes met streepjes ertussen. Dat is om aan te geven dat je iets kan delen. Als je het ikoontje aanklikt, krijg je een nieuw menu aan de rechterkant. Je kan een emailadres of de naam van iemand anders invullen om rechtstreeks te sturen, of je kan op ‘share link’ klikken om een hyperlink klaar te zetten. Die link moet je daarna zelf aan iemand sturen: met een email, overschrijven of een ander berichtje.
Klaar!
Je foto is nu bereikbaar voor iedereen aan wie je de link stuurt, of enkel voor degene aan wie je de email stuurde. Wat die mensen vervolgens doen weet je maar nooit, als je eenmaal iets gedeeld hebt op internet, is het voor altijd gedeeld.
Behalve de foto zelf delen, kun je ook iets over de foto zeggen, of andere mensen er iets over laten zeggen. Iedereen met een account op je Yunohost kan dat in ieder geval, maar je kan ook vrienden op hun eigen Nextcloud rechtstreeks benaderen. Het is me nog niet goed gelukt dat te laten werken, wordt vervolgd.